FTPDB
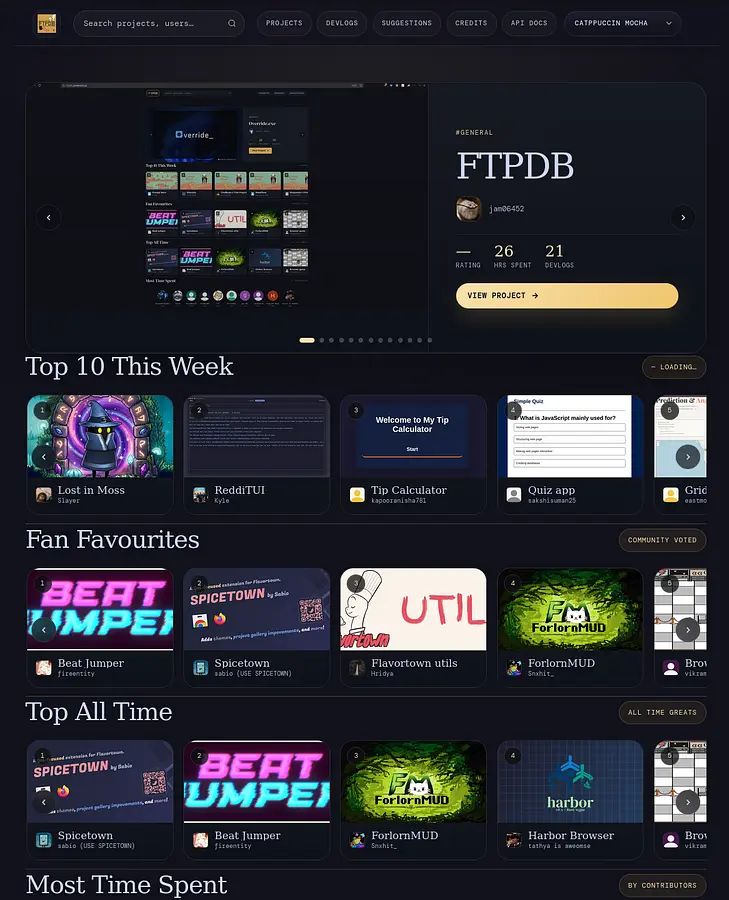
An IMDb-style database for Flavortown projects, users, and devlogs
About
Flavortown is a platform where people log hours working on personal projects and share devlogs as they go. It’s a great concept, but its native search and browsing experience is limited — you can’t easily filter by activity, sort by popularity, or quickly look up what someone has been building. FTPDB fixes that.
FTPDB (FlavorTown Project Database) is an IMDb-style interface that scrapes the entirety of Flavortown, stores it in a custom Postgres database, and serves it through a fast, searchable frontend built in Elixir and Phoenix LiveView. It has a public API, markdown-rendered devlog pages, user profiles, a ranking algorithm, and sub-millisecond response times for most queries.
Some Flavortown admins have ended up using it as their primary way to look up projects. That was never the original goal, but it’s a reasonable sign that the problem being solved is real.
The Build
Starting from Scratch: Scraping Flavortown
The first challenge was getting the data. Flavortown exposes an API, but it wasn’t designed for bulk access — so the initial pass involved writing a Python scraper to pull in every project, user, and devlog and load it into Supabase.
This sounds straightforward until it isn’t. A few things went wrong immediately:
Missing devlog project IDs. A chunk of devlogs in the API response didn’t include their parent project ID. The bulk /devlogs endpoint wasn’t reliable enough to reconcile these on its own, so a secondary scraping pass was needed — hitting /projects/{id} and /devlogs/{id} individually for every affected record. This meant the scraper had to be smart enough to detect the gaps, queue the affected IDs, and fill them back in. It also hit rate limits hard during this pass, which slowed things down considerably.
Images. The original plan was to host images locally. That fell apart quickly — there simply isn’t enough disk space to store banners for every project on Flavortown. The solution was to reference images directly from Flavortown’s CDN rather than re-hosting them. This works, but it means image load times are at the mercy of Flavortown’s servers, not mine.
Concurrency for banner scraping. Once image URLs were being fetched separately, banner scraping became a bottleneck. Running 40 concurrent workers for the banner fetch pass brought this down to an acceptable time. The scraper also supports a full rescrape of banners — not just filling in null values — so it can be re-run from scratch if needed.
All of this is managed through a TUI (terminal user interface) that ties together the various scraping scripts into a single control panel, rather than having to remember which Python file does what.
The Live Scraper
A one-time import only gets you so far. To keep data current, a live scraper runs every 30 seconds against the /projects and /devlogs Flavortown API endpoints and diffs the results against what’s already in the database.
This is where the upstream API becomes a constraint rather than just an inconvenience. The Flavortown API doesn’t always return up-to-date data — hours and stats in particular lag behind the actual state of a user’s account. This isn’t something that can be fixed from the outside; the note on the FTPDB homepage (“Hours & Stats MAY not be accurate due to the FT API not working as intended”) is there because of this, not because of any bug in the scraper. The scraper does what it can with what it gets.
Backend: Elixir & Phoenix
The web application is built entirely in Elixir using the Phoenix LiveView framework. The choice of Elixir here is the same reasoning as the URL shortener — the BEAM VM handles concurrent, independent requests extremely well, and LiveView means the interactive parts of the UI (search, shuffle, theme switching) work without writing a separate JavaScript frontend.
All database logic lives in DB.ex, split into sections for misc, projects, users, and devlogs. This separation makes the file navigable as the number of functions grew over time, and it made the refactoring passes easier — there were several of these as the codebase matured.
Supabase RPCs. Several operations that would be prone to race conditions or slow if done in application code are instead handled by stored procedures (RPCs) called directly through Supabase. Random project selection is a good example: rather than pulling a large set and shuffling in Elixir, the RPC handles true randomness at the database level. Projects with default banners are filtered out server-side too, since these tend to be starter templates with no meaningful content.
Ranking. Hot projects are ranked by an algorithm that weighs recent activity, total likes, and time logged. Fan favourites weight purely on likes. Top this week filters by activity within the current week. These are all exposed as separate API endpoints and used by different sections of the frontend.
Slack integration. A /suggestions page sends user-submitted feedback directly to my Slack via a bot. It’s a simple webhook call but it means suggestions actually reach me rather than disappearing into a form.
Caching
Random project and devlog loading initially took around 5 seconds. That’s not acceptable for something that’s supposed to feel instant.
The fix was Cachex, an Elixir in-memory caching library, combined with a rethought selection strategy:
- Pick a random index from 1 to the total number of projects/devlogs
- Use that index as a cache key
- On a cache miss, fetch from Supabase and populate the cache
- On a cache hit, return immediately
The key insight was that “random” doesn’t need to mean “uncached”. A random index into a cached set is still random from the user’s perspective, and it means the hot path doesn’t need to touch the database at all after the first request. This brought random load times from ~5 seconds down to around 40ms. The same logic applies to both random projects and random devlogs.
Cloudflare provides an additional edge caching layer on top of this, so even the Phoenix app doesn’t need to be hit for cacheable pages.
Frontend
The frontend is Phoenix LiveView with .html.heex templates — no separate JavaScript framework. Early iterations had CSS scattered across individual component files, which became a maintenance problem as the number of pages grew. A consolidation pass moved everything into a single stylesheet, which made component reuse straightforward and noticeably shrank the codebase.
Search uses relevance ranking that accounts for hotness and like count, so you don’t just get alphabetical results. It’s also case-insensitive and excludes deleted projects from results, both of which sound obvious but had to be explicitly added.
Project pages show the project banner, total time logged, like count, the full list of devlogs, and a link to the project’s page on Flavortown itself. Devlogs render full markdown, including images — this was added after noticing that a lot of devlogs include formatted text and screenshots that looked broken as plain text.
User pages show profile picture, display name, Slack ID (useful for finding someone quickly), total time across all projects, and a grid of their projects.
Random browsing. There’s a /projects page with a shuffle button that serves a random selection from the cache. Same for devlogs. These existed before the caching work but were too slow to be useful — at 40ms they’re actually fun to use.
Theme switching. Two colour themes, toggled without a page reload.
Scroll arrows. The default scrollbar on tiled project views was hard to spot. Arrow buttons were added as an explicit navigation affordance.
Error handling. If a project has been deleted but a user still exists, returning nil to the frontend used to cause a crash. The backend now handles this gracefully and returns the user’s projects regardless.
The Logo
The logo was made by @SeradedStripes, not me. It’s better than anything I would have produced. There’s a favicon version too.
API & Docs
FTPDB exposes a public API. The docs are hosted on Scalar rather than within the app itself — Scalar gives a much nicer presentation than a raw OpenAPI YAML file served locally. The OpenAPI schema was rebuilt from scratch based on the original spec and is kept in sync as endpoints change.
Performance
| Operation | Before | After |
|---|---|---|
| Random project load | ~5s | ~40ms |
| Random devlog load | ~5s | ~40ms |
| Response time (cached) | — | ~150µs |
What I Learned
Scraping in bulk is a negotiation with the upstream API. Rate limits, missing fields, and stale data aren’t edge cases — they’re the norm. The scraper needed to be robust enough to handle partial failures, queue retries, and reconcile gaps rather than assuming the first pass would be complete.
Caching strategy matters more than raw database speed. The move from 5 seconds to 40ms wasn’t about switching databases or optimising queries — it was about rethinking when and how data is fetched at all. A well-designed cache makes a Postgres round-trip feel local.
Consolidating CSS early would have saved time. The refactor to a single stylesheet happened after a dozen pages had their own styles. Doing it sooner would have avoided duplicate work and made the UI more consistent from the start.
Community adoption changes how you prioritise. Once Flavortown admins started using the search bar, fixing bugs in search accuracy moved up the list. Building for real users — even a small number — is different from building for yourself.
Tech Stack
- Web — Elixir, Phoenix LiveView
- Scraper — Python (containerised, with TUI)
- Database — Supabase (Postgres)
- Caching — Cachex (application-level), Cloudflare (edge)
- API Docs — Scalar
- Infrastructure — Oracle Cloud VM, Docker, GitHub Actions